Model Inference
Contents
Source Code
Please refer to Model Inference for the source code (Jupyter Notebook).
Predictor Importance
We choose Gradient Boosting Regression as the best model to predict playlist popularity. This model has high interpretablilty, enabling us to analyze the most important features and qualities of popular playlists. To evaluate the importance of predictors for the gradient boosting tree, we use scores determined by the usefulness of the certain predictor during the construction of trees.
Breiman et al. (1984) proposed that the following formula can be used to find the importance of a predictor variable for one given tree. [1]
For a tree $T$, the importance of variable $X_l$ is summed over $J-1$ nodes of the tree. $I(v(t)=l)$ indicates whether predictor $X_{v(t)}$ was used to split the node, $\hat{i_t}^2$ is the estimated improvement in squared error risk. Because the method used is an ensemble of trees, the total importance of predictors is given by the sum of this value over all (M) trees, given below.
The predictors are evaluated in importance for each broad category (artist/genre/audio feature) of predictors considered. The top 50 were chosen out of the total 949 predictors.
GradientBoostingRegressor(alpha=0.99, criterion='friedman_mse', init=None,
learning_rate=0.03, loss='huber', max_depth=5,
max_features='auto', max_leaf_nodes=None,
min_impurity_split=1e-07, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
n_estimators=200, presort='auto', random_state=None,
subsample=1.0, verbose=0, warm_start=False)
Important Audio Features
In general, the most important category of features was found to be the audio features. In fact, 24 out of the most important 50 were audio features.
| Feature | valence_mean | dance_mean | valence_std | speech_std | liveness_mean | loudness_std | speech_mean | mode_mean | acousticness_std | followers_std | tempo_std | instrumentalness_std | key_mean | time_mean | liveness_std | loudness_mean | dance_std | tempo_mean | energy_mean | key_std | acousticness_mean | followers_mean | energy_std | instrumentalness_mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Importance Percentage | 100.0 | 92.459074 | 77.060993 | 56.463127 | 53.478693 | 47.417054 | 43.054002 | 40.359594 | 38.34399 | 38.3274 | 37.664597 | 35.477903 | 30.910104 | 30.734492 | 28.425508 | 28.27619 | 27.195735 | 26.276604 | 23.364516 | 21.360647 | 20.730889 | 20.210386 | 19.774391 | 11.737473 |
Interestingly, the mean valence is shown to be the most important predictor. The valence of a song is defined by the mood of the song–whether it is a happy song (high valence) or a sad/angry song (low valence). We observe that both visually and with multiregression, valence is negatively correlated to playlist followers. Both the mean and the standard deviation are highly significant predictors, indicating that not only do people want to hear sad and depressing songs, but they prefer playlists that are mostly composed of consistent sad and depressing songs!
The second most important predictor is the mean of danceability. Songs that are more danceable have greater tempo and rhythm stability, beat strength, and overall regularity.
Another important predictor is the speech standard deviation and mean. We also observe in the multi-regression inference that there is a negative correlation between speech and playlist popularity. This indicates that followers consistently prefer songs with less speech.
Important Genre Features
| Importance Percentage | Num_tracks | Mean_Follow | Total_Follow | Std_Follow | |
|---|---|---|---|---|---|
| Feature | |||||
| 'hip house' | 14.837564 | 35.0 | 394870.0 | 13820445.0 | 8.255246e+05 |
| 'dance-punk' | 14.232088 | 384.0 | 240562.0 | 89970041.0 | 4.815128e+05 |
| 'hardcore hip hop' | 12.197885 | 433.0 | 287570.0 | 121354445.0 | 1.001567e+06 |
| 'slow core' | 10.253461 | 37.0 | 393312.0 | 14159226.0 | 6.365066e+05 |
| 'indie poptimism' | 9.682095 | 771.0 | 261538.0 | 197199914.0 | 8.365860e+05 |
| 'movie tunes' | 9.477833 | 203.0 | 306781.0 | 59822247.0 | 6.800909e+05 |
| 'escape room' | 8.226294 | 521.0 | 233039.0 | 118616861.0 | 5.229733e+05 |
| 'compositional ambient' | 8.218600 | 375.0 | 272666.0 | 100613579.0 | 5.892620e+05 |
| 'adult standards' | 8.161076 | 476.0 | 251238.0 | 115569352.0 | 6.626870e+05 |
| 'brill building pop' | 7.742838 | 72.0 | 252205.0 | 17654320.0 | 6.561112e+05 |
We can see from the table that significant genres include compositional ambient, dance-punk, welsh rock, hardcore hip hop, hip house, adult standards, escape room, and slow core.
These may not be the most common genres, in fact the number of tracks in each of these genres are all below 600. However, we do see that for all of these genres, the mean number of followers is significantly higher. The recently booming popularity of escape rooms is a possible cause of the popularity of escape room music. We notice that these genres, although not frequently featured in playlists, may have very loyal and consistent listeners.
Important Title Features
The most important titles include years in the 2000s. Titles with 1990s are also significant, although lesser in degree. It is reasonable that people search for recent songs more often.
Important Interaction Features
The most important interaction we see is how much liveness differs for songs in a track, for pop music. Liveness refers to whether the track is likely to be performed live. In general, we see that the more likely a track is recorded live, the less number of followers the track would have. This relationship is particularly critical for pop and dance music.
We observe that acousticness is an important feature for several different genres: hip hop, house, acoustic, and r&b.
Lastly, how much energy and key may differ for songs in rap playlists is also quite significant.
Important Artists
artist_followers_df = pd.read_csv('data/artist_level_EDA.csv')
| Importance Percentage | Mean Followers | |
|---|---|---|
| Yo Gotti | 17.104839 | 1.171835e+06 |
| Post Malone | 8.293600 | 1.380026e+06 |
We observe that the most significant artists were Yo Gotti, Led Zeppelin, and Post Malone. They are all of artists of different genres: Yo Gotti is an American rapper, Led Zeppelin an English rock band, and Post Malone an American rapper/singer/songwriter/guitarist. They all have a large number of mean followers for playlists they are featured in.
| Feature | Importance Percentage | |
|---|---|---|
| 0 | popularity_std | 71.277682 |
| 1 | popularity_mean | 36.864343 |
Unsurprisingly, the popularity of the artist has a great significance on the popularity of the playlist. What is surprising is that the standard deviation of artist popularity songs has a greater significance than the mean of the popularity. This indicates that a playlist having consistent artist popularity will gain more followers.
Inference for Residuals
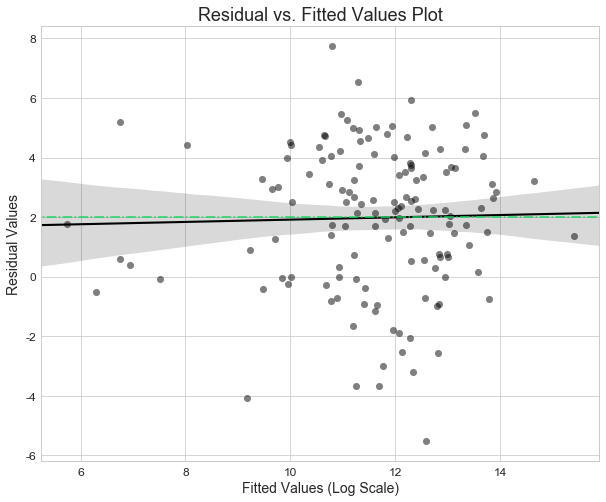
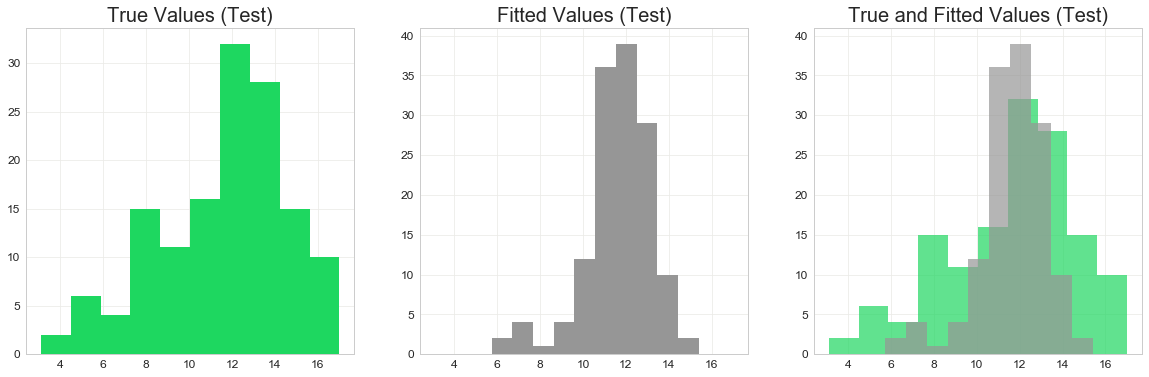
The residuals plot above shows the difference between the predicted fitted values and the actual values, $\hat{y}-y$. The plot shows a pattern that is similar to a diamond. We observe that they are very dense around 12 (in log scale). A possible cause of this pattern in the residuals plot is the distribution of the response (in log scale), which is slightly left skewed. This is shown below. Consequently, the residuals will be high around 12. We can also observe that the distribution of the fitted values is narrower than the true response. Overall, the residuals seem to show heteroskedasticity which may require further investigation in future works.
References:
[1] Hastie, T., Tibshirani, R., & Friedman, J. H. (2001). The elements of statistical learning: Data mining, inference, and prediction. New York: Springer.