Contents
Performance Evaluation
This section will provide a performance overview across the various (parallel) implementation types and will mostly touch on strong scaling analysis (i.e., given a problem size, how does wall time vary for different number of nodes, processors and/or threads).
Serial Execution
As a baseline, the serial code was compiled without any optimization flags and run across varying domain sizes.
Serial (No Flag) - Ra=5000:
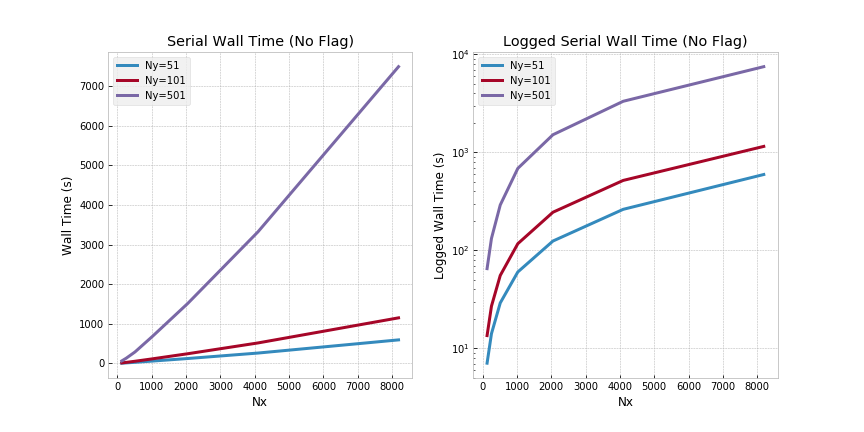
Based on the above results, two observations follow: (i) wall time (even for relatively small domain sizes) quickly becomes a major bottleneck; (ii) higher Rayleigh numbers further exacerbate the wall time increase. These observations are evidence that the serial code base quickly becomes intractable for either large domains or high Rayleigh numbers (both of which are interesting from a research perspective).
Optimization Flags
The first step in optimizing the serial code was to include an aggressive optimization flag when compiling. Specifically, an -O3 flag was used and the resultant temperature fields and Nusselt numbers were confirmed to yield the consistent results.
Serial (-O3 Flag) - Ra=5000:
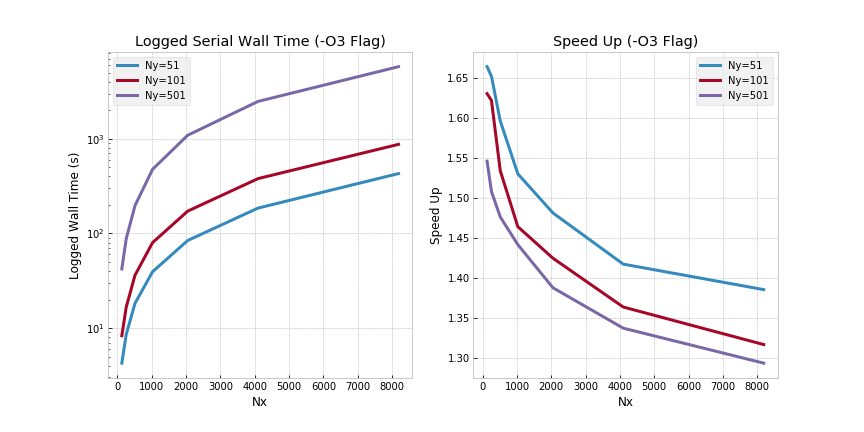
Although speed up for small domain sizes is meaningful, the decrease in wall time quickly tapers off as larger domains are analyzed. Clearly, whilst including an aggressive optimization flag is helpful, it is not the solution for large scale analysis.
MPI FFTW & Optimization Flags
As outlined here, the two-dimensional domain at hand was decomposed across both axes. Specifically, in the x-direction (i.e., horizontal direction), a pencil decomposition was implemented using (FFTW) MPI. To benchmark performance, two execution approaches are analyzed. These are: (i) No Shared Memory (i.e., running on a single node where each core/processor is assigned a separate MPI task); and (ii) SMP Sockets/Nodes (i.e., running MPI tasks per socket/node and where threads share local memory).
MPI on 1 Node - Ra=5000:
Refer to the below graphs for an overview of wall times across varying Ny, Nx and number of processors.
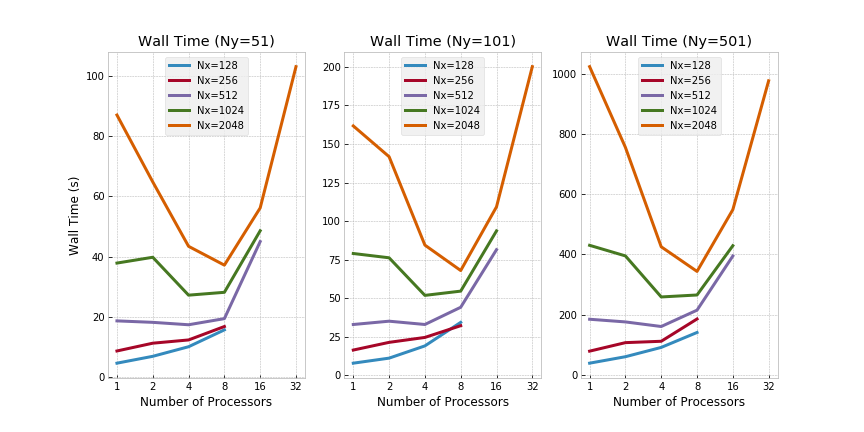
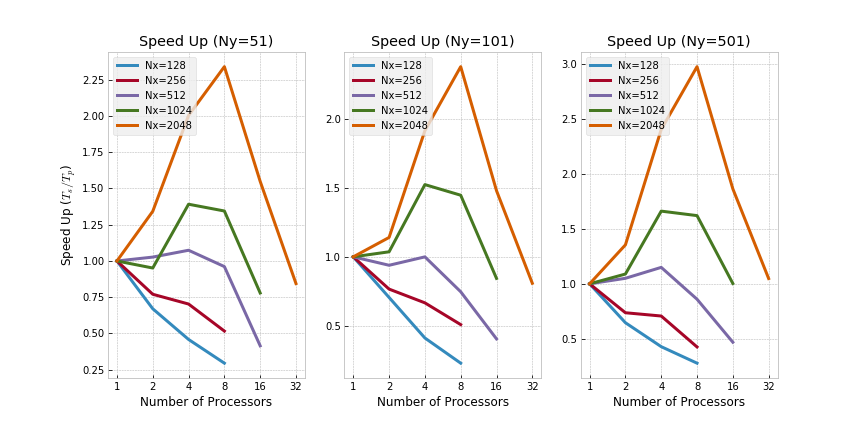
Evidently, running MPI on a single node seems to introduce significant overhead as expected. As a direct consequence, running MPI on small domains (e.g., for Nx=128 and Ny=51) is counterproductive from a wall time perspective - the overhead introduced by message passing outweighs the speedup through parallelism in those cases. Speedup has been calculated as
Speedup graphs are shown below for more information.
Finally, the efficiency of parallelism is analyzed next where efficiency is defined as
Clearly, the relative bang for buck drastically decreases as more processors are used.
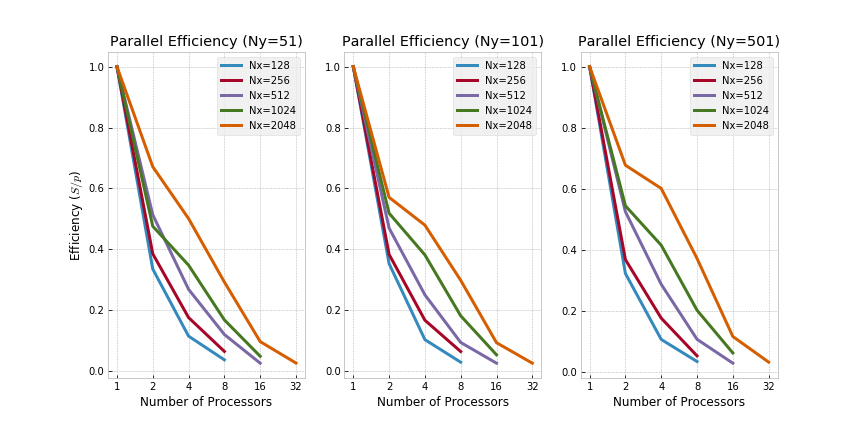
MPI on 8 Nodes - Ra=5000:
Clearly, the main rationale for using MPI is not necessarily to run multiple tasks on a single node - contrarily, it is to run multiple tasks on multiple nodes (i.e., distributed memory). To this extent, 8 nodes were used to run the code across relatively large domain sizes (i.e., up to Ny=501 and Nx=65536). Refer to the below plots for the (i) execution wall times, (ii) speed up and (iii) efficiencies.
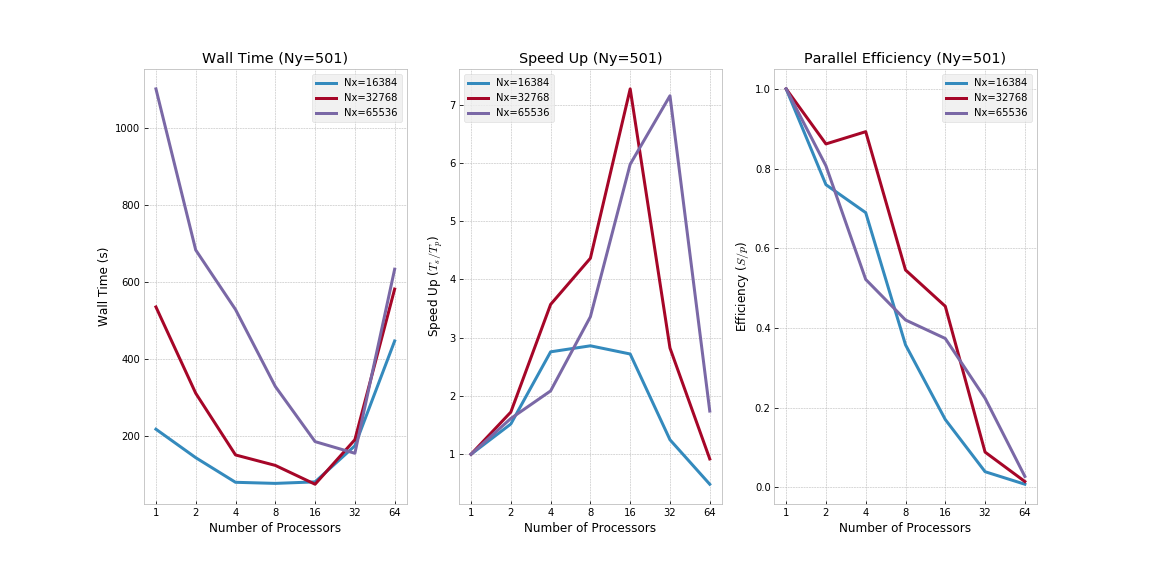
Note that the shown speedup is versus the serial code base (i.e., running on a single processor). Effectively, this means the observed speed up is slightly sublinear in number of nodes when using MPI (c. 7x speed up for 8 nodes under the tested domain size and Rayleigh number).
OpenMP & Optimization Flags
As outlined under the Implementation section, the two-dimensional domain was decomposed in the y-direction (i.e., vertical or wall-normal direction) using OpenMP. Specifically, across all major Ny-loops, Fortran OMP PARALLEL DO statements were introduced. Refer to the below plots for more information in terms of resultant wall time, speed up and efficiency.
OpenMP - Ra=5000:
Evidently, speed up from multithreading (using OpenMP) is limited. The potential rationale for this observation is twofold: (i) by far the most time-consuming aspect of the code is the frequent usage of Fast Fourier Transforms - given the OpenMP parallelization does not necessarily speed up those calls, only limited speed up can be expected; and (ii) the discretization in y-direction is non-uniform (i.e., using a cosine grid) - as such, load balance across threads can be highly skewed.
Hybrid MPI/OpenMP & Optimization Flags
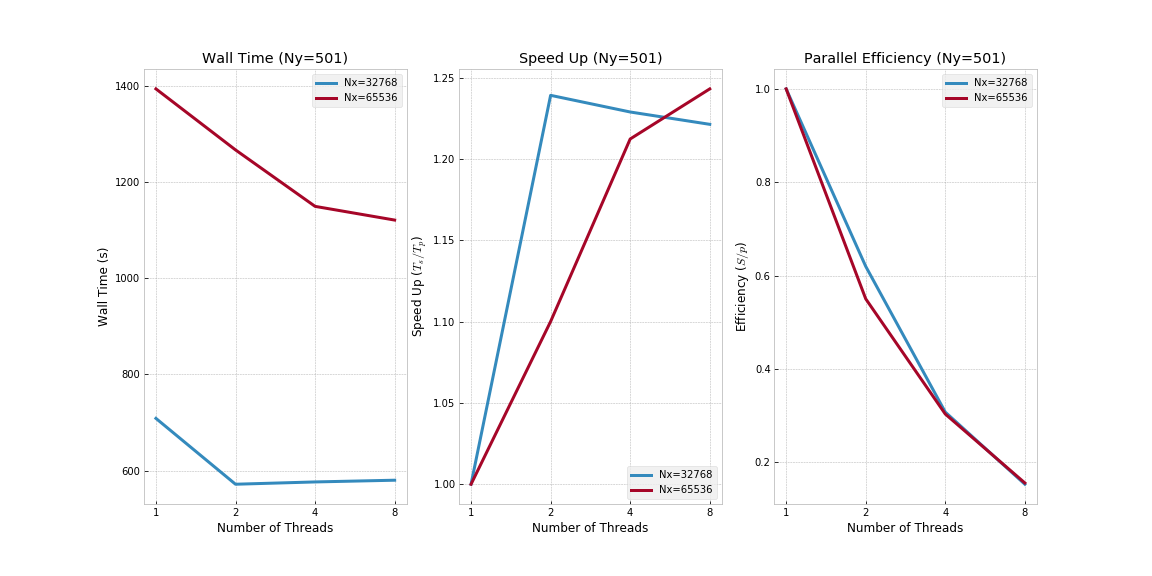
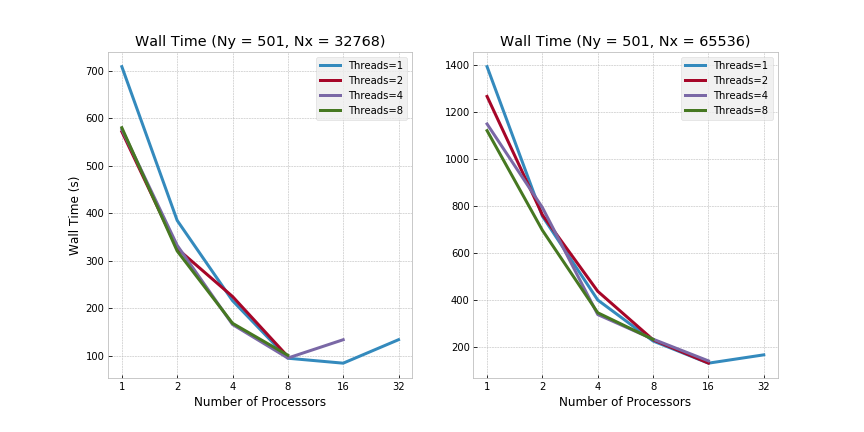
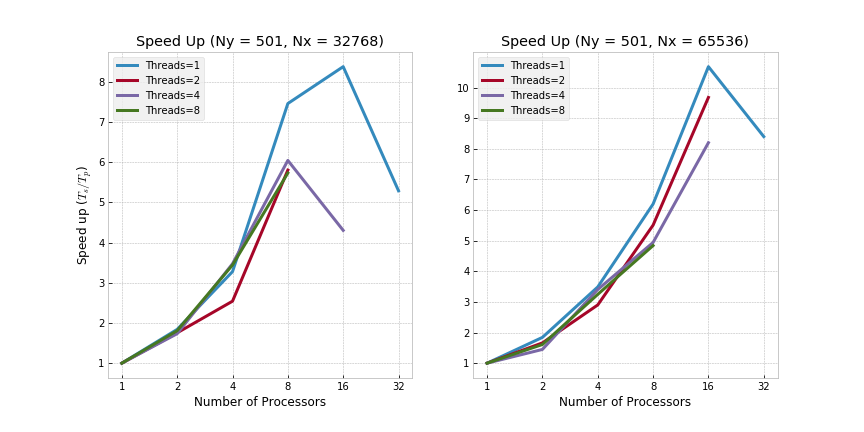
Finally, both MPI and OpenMP were implemented concurrently using a hybrid approach where parallelization in x-direction was achieved by FFTW MPI and in y-direction by OpenMP. Specifically, in terms of benchmarking, a total of 8 nodes were used with up to a total of 32 cores and 8 threads per core. The resultant wall times across large domains (Ny=501 and Nx=32768/65536) are shown below.
MPI/OpenMP on 8 Nodes - Ra=5000:
Note that the shown speedup is versus the serial code base (i.e., running on a single processor). Effectively, this means the observed speed up for the hybrid approach (MPI/OpenMP) is superlinear in number of nodes (c. 10x speed up for 8 nodes under the tested domain size and Rayleigh number).
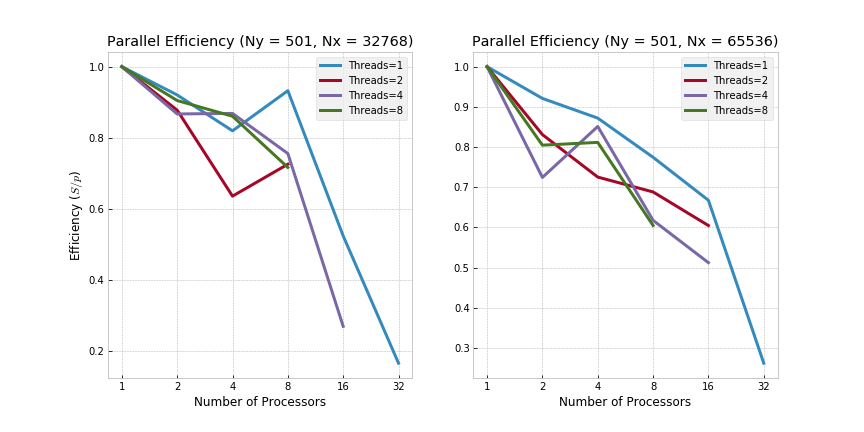
In terms of efficiency, relative bang for buck decreases as more processors are used as seen before (i.e., the marginal increase in speed up diminishes as more threads and/or cores are used).
Summary of Results
A number of observations are worthwhile summarizing at this stage. Specifically:
- Serial execution quickly becomes intractable for large domains and/or high Rayleigh numbers
- Use of compiler optimization flags is helpful for small domains, but quickly becomes relatively less effective as domains increase in size
- MPI introduces significant overheads (e.g., through message passing)
- For small domains, the introduced overhead may outweigh the benefit of parallelism (and hence lead to larger wall times)
- For large domains, the speed up is significant and only slightly sublinear in number of nodes (under the tested domain size and Rayleigh number)
- Use of OpenMP improves performance across loops in Ny but is limited in overall speed up by FFT executions in x-direction
- The hybrid approach across MPI/OpenMP introduces even more overhead than MPI alone (e.g., through blocking and/or load imbalance)
- For small domains, it may not make sense to use the hybrid approach given the introduced overhead outweighs the benefit of parallelism
- For large domains, the speed up is significant and superlinear in number of nodes (under the tested domain size and Rayleigh number)